https://towardsdev.com/kafka-101-a-beginners-guide-to-understanding-kafka-2cd797864614
Kafka 101: A Beginner’s Guide to Understanding Kafka
Apache Kafka has become a critical infrastructure tool for building real-time data pipelines, event-driven architectures, and streaming applications. However, its terminology, architecture, and…
towardsdev.com
Kafka에서 핵심이 되는 구조는
토픽(Topic), 파티션(Partition), 브로커(Broker), 컨슈머 그룹(Consumer Group)이다.
Kafka의 토픽은 하나의 데이터 스트림을 저장하는 단위이고,
이 토픽은 여러 개의 파티션으로 나뉘어진다.
각 파티션은 실제 데이터가 저장되고 처리되는 최소 단위이다.
파티션은 항상 하나의 리더 브로커(Leader Broker)가 담당하고,
나머지 브로커들은 팔로워(Follower)로서 리더의 데이터를 복제하는 역할을 한다.
리더 브로커는 모든 읽기/쓰기 작업을 담당하고, 팔로워 브로커는 단순히 데이터를 백업하는 역할만 한다.
리더 브로커가 죽으면, 팔로워 브로커 중 하나가 리더로 승격되어 무중단 장애 복구가 가능하다.
복제되는 단위는 파티션이며, 하나의 브로커는 여러 토픽의 여러 파티션을 가질 수 있다.
Kafka에서 컨슈머 그룹은 하나의 목적을 가진 소비자 집합이다.
컨슈머 그룹 안에서는 각 파티션을 나눠서 읽으며,
한 파티션은 동시에 한 컨슈머만 읽는다.
같은 컨슈머 그룹 내에서는 한 파티션을 여러 컨슈머가 동시에 읽을 수 없다. (메시지 순서를 보장하기 위해서)
반면, 서로 다른 컨슈머 그룹들은 같은 토픽을 독립적으로 읽을 수 있다.
서로 영향을 전혀 주지 않고, 각자 별도의 오프셋(Offset, 읽은 위치)을 관리한다.
Kafka는 컨슈머 그룹마다 별도로 오프셋을 관리한다. 오프셋 정보는 내부 토픽인 __consumer_offsets에 저장된다.
만약 A라는 토픽을
김 컨슈머 그룹, 최 컨슈머 그룹, 박 컨슈머 그룹이 각각 읽고 있다고 해보자.
이때 김 그룹이 엄청 빠르게 모든 메시지를 읽어버리더라도,
최 그룹과 박 그룹은 자기들의 오프셋을 기준으로 천천히 읽는다.
김 그룹이 빨리 읽는다고 해서 다른 그룹의 읽을 수 있는 데이터가 없어지지 않는다.
Kafka는 메시지를 읽었다고 바로 삭제하지 않는다.
메시지는 설정된 Retention 기간(예: 7일) 동안 유지되고, 기간이 지나야 삭제된다.
만약 Retention 기간 안에 컨슈머 그룹이 메시지를 다 읽지 못하면,
Kafka는 메시지를 삭제하고, 남아있는 컨슈머 그룹은 OffsetOutOfRangeException 같은 에러를 만나게 된다.
과거 spring에 elk 붙혔던 것에서 logstash -> kafka 로 변경했다고 가정하면,
elk 스택을 활용한 데이터베이스 연동
https://github.com/LuckyVickys/woosan-back| 도입 우산 프로젝트는 ElasticSearch를 사용해서 검색 기능을 구현했다.구현이 용이하도록 간단하고 쉽게 설계한 뒤, 네이버 클라우드 플랫폼 바우처가 있을 때
99duuk.tistory.com
Kafka에서는 소스 시스템 하나에서 발생한 이벤트를, 여러 컨슈머 그룹이 각각 다른 방식으로 소비할 수 있다.
- 로그 수집용 컨슈머 그룹
- 타겟 시스템 전송용 컨슈머 그룹
- 초성 추출용 컨슈머 그룹
- 검색어 수집용 컨슈머 그룹
이렇게 분리할 수 있다. 각 컨슈머 그룹은 독립된 오프셋을 가지고, 같은 메시지를 읽더라도 각자의 목적에 맞게 처리할 수 있다.
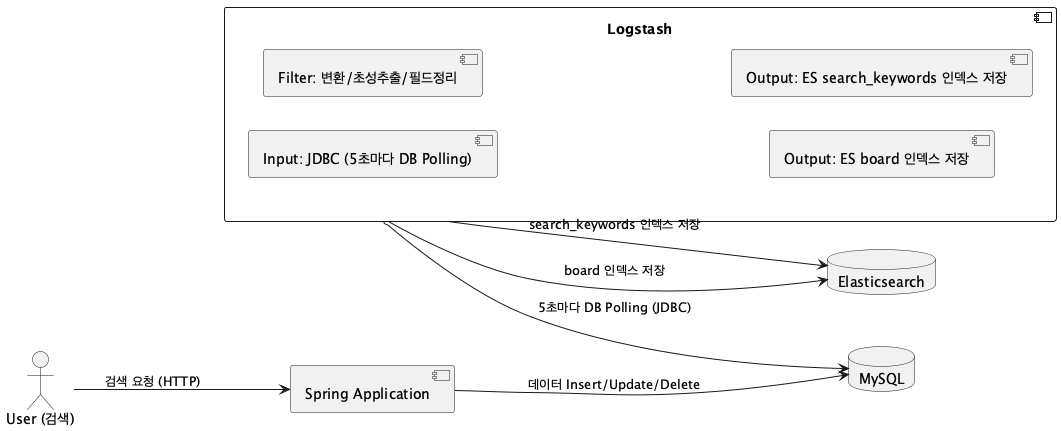
- Input (JDBC)
- MySQL에서 5초마다 주기적으로 데이터 변경을 폴링했다.
- sql_last_value를 기준으로 변경된 데이터만 가져왔다.
- Filter
- 필요 없는 필드를 제거하고, 새로운 메타데이터를 추가했다.
- title과 content를 복사하여 synonym 필드를 만들었다.
- ruby 코드를 이용해 한글 초성 추출을 수행했다.
- Output
- board 인덱스로 게시글을 저장하거나 삭제 처리했다.
- 검색어 수집은 search_keywords 인덱스에 저장했다.
하지만 이 구조는 기본적으로 주기적인 폴링(Pull) 기반이었고, 하나의 Logstash 프로세스가 모든 역할(동기화, 초성추출, 검색어 저장 등)을 담당하는 구조였다.
Kafka로 구조를 변경하면 다음과 같은 변화가 생긴다:
- 소스 시스템(DB 등)에서 변경이 발생할 때마다 Kafka Producer가 토픽에 메시지를 발행한다. (Push 방식)
- 토픽은 목적별로 여러 컨슈머 그룹이 구독할 수 있다.
- 각각의 컨슈머 그룹은 독립적으로 메시지를 소비하고, 별도로 가공 및 저장할 수 있다.
예를 들면:
- es-sync-group: 원본 데이터 Elasticsearch 저장
- chosung-extract-group: title, content 초성 추출 후 저장
- tokenizing-group: 문장 토크나이징 후 저장
- search-tracking-group: 검색어 조회 기록 저장
이렇게 구분할 수 있다.
가벼운 작업(초성 추출, 검색어 저장)끼리는 하나로 묶을 수도 있다.
묶을지 분리할지는 리소스 사용량, 작업 복잡도에 따라 결정하면 된다.
만약 특정 작업(예: 토크나이징)이 CPU, 메모리를 많이 잡아먹어서 병목이 생긴다면,
- 해당 컨슈머 그룹의 컨슈머 수를 늘리고,
- 토픽의 파티션 수도 늘려서 병렬 처리를 강화할 수 있다.
Kafka에서는 다음과 같은 Partition 설계 방법이 필요하다:
- 예상하는 컨슈머 수 이상으로 파티션을 만든다.
- 초당 데이터 처리량을 고려해서 파티션 수를 잡는다. (보통 1파티션당 1~10MB/s 기준)
- 키를 잘 설정해야 한다. (user_id, order_id 등 고유한 식별자 사용 추천)
- 파티션은 줄일 수 없고, 늘릴 수만 있으니 처음에 여유 있게 잡는다.
Consumer Lag이 발생하면 (즉, 아직 읽지 못한 메시지가 쌓이면):
- 컨슈머 수를 늘리거나,
- 파티션 수를 늘리거나,
- 컨슈머 코드 최적화 (병목 줄이기)를 해야 한다.
Consumer Lag은 실시간 모니터링 도구를 이용해서 관리하는 것이 중요하다. (Kafka Manager, Burrow 등)
Consumer Commit 방법에도 주의해야 한다:
- auto.commit은 주기적으로 자동 커밋되지만 신뢰성이 떨어진다.
- manual commit은 처리 완료 후 명시적으로 커밋해서 데이터 손실 위험을 줄일 수 있다.
Kafka는 단순히 메시지 큐가 아니라, 대규모 분산 스트리밍 플랫폼이다.
- 파티션으로 수평 확장,
- 컨슈머 그룹으로 목적 분리,
- 실시간/병렬 처리,
- 장애 복구,
- 다양한 스트리밍 패턴(Exactly-once, At-least-once, 등)까지 지원한다.
Kafka로 변경하면서 실시간성, 확장성, 장애 격리성, 유연성이 기존 Logstash Polling 기반 구조보다 훨씬 좋아진다.
마지막으로, 이 흐름을 PlantUML로 시각화했다.

'기타' 카테고리의 다른 글
| 장자 길라잡이 76 - 두려워 말라 (0) | 2025.12.30 |
|---|---|
| 지피티야 미안해 (0) | 2025.06.29 |
| 전략 패턴 (0) | 2025.04.28 |
| ArrayList와 HashSet 만들어보기.. C++ (1) | 2025.03.03 |
| Vim 마스터의 길... (0) | 2025.03.03 |