ROLLUP을 이용한 부서별/직무별/성별 인원 및 급여 통계
MYSQL에서는 GROUP BY ... WITH ROLLUP 구문을 이용하여, 집계 결과로 생성되는 NULL 값들을 구분하기 위해 GROUPING() 함수를 사용할 수 있다.
GROUPING(col) = 1 이면 해당 행이 ROLLUP에 의해 생성된 소계/총계 행이라는 의미다.
이를 응용하여, NULL 대신 '전체' 등의 라벨을 표시하면 결과를 이해하기 쉬워진다.
ROLLUP은 컬럼의 순서에 따라 점진적으로 상위 수준의 총계를 계산한다.
- 컬럼 리스트를 계층적으로 줄여가며 총계를 만듦
- ex) GROUP BY A, B, C WITH ROLLUP
(A, B, C): 개별 데이터.
(A, B): C에 대한 총계.
(A): B, C에 대한 총계.
(): 전체 총계
rollup을 사용하면 다중 수준의 집계 결과(부분합과 총합)을 자동으로 계산할 수 있다.
부서별, 직무별, 성별로 직원 수와 급여 합계를 집계하고, 각 부서별 소계(모든 직무 합계), 전체 총계를 출력해보자!
SELECT
IF(GROUPING(d.dept_name)=1, '전체 부서', d.dept_name) AS dept_name,
IF(GROUPING(j.job_title)=1, '전체 직무', j.job_title) AS job_title,
IF(GROUPING(e.gender)=1, '전체', e.gender) AS gender,
COUNT(*) AS emp_count, -- 직원 수
SUM(e.salary) AS total_salary -- 급여 총합 (합계)
FROM employees e
JOIN departments d ON e.dept_id = d.dept_id
JOIN jobs j ON e.job_id = j.job_id
GROUP BY d.dept_name, j.job_title, e.gender WITH ROLLUP;
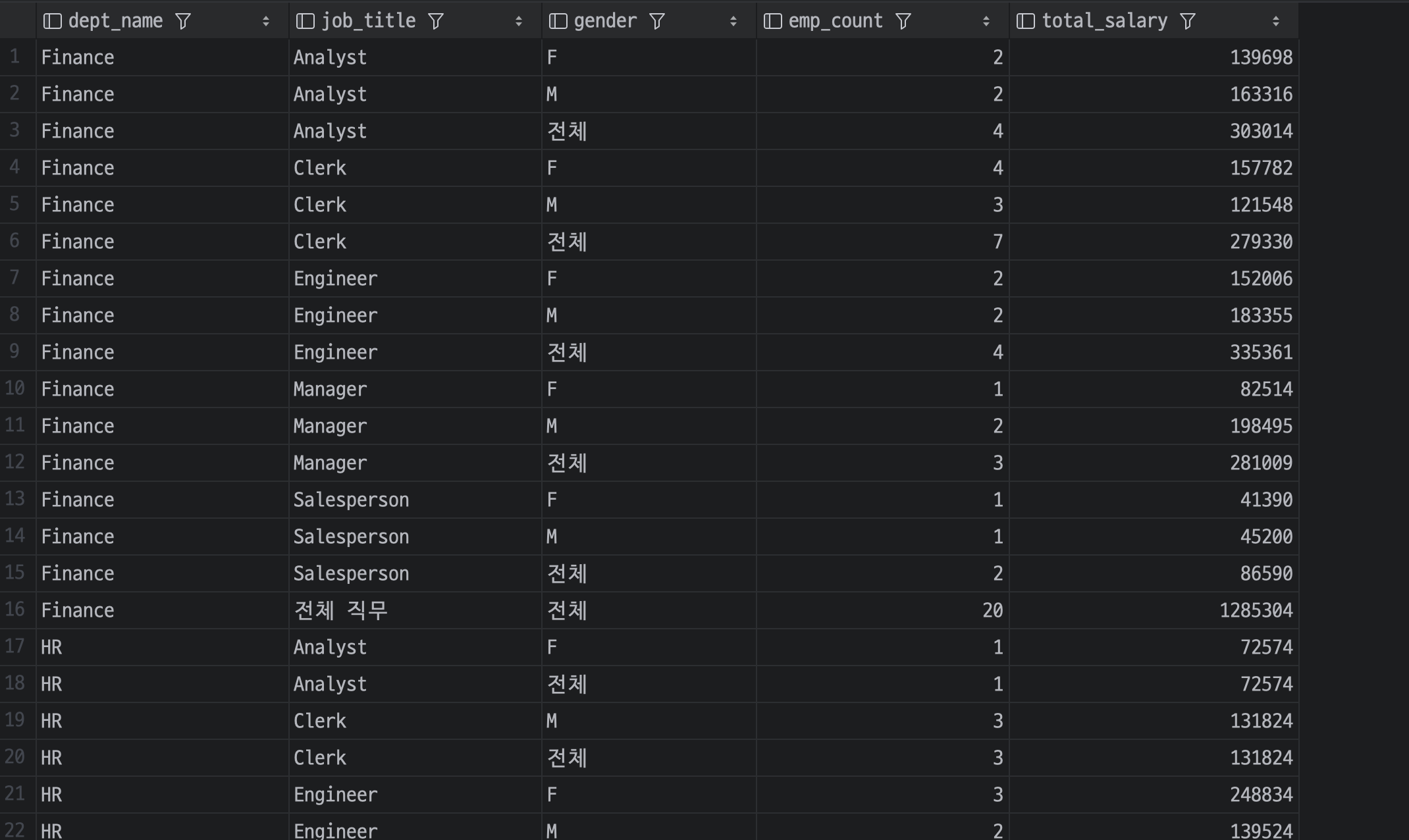
요로코롬 WITH ROLLUP을 사용함으로써 부서별/직무별 세부내역과 함께 부서별 합계, 전체 합계를 계층적으로 얻었다.
그리고 GROUPING()을 사용해 '전체' 라벨을 붙혀 가독성을 높일 수 있긔;;
+ 합계행을 상단에 올려버리고 싶으면
ORDER BY
GROUPING(d.dept_name) DESC, d.dept_name,
GROUPING(j.job_title) DESC, j.job_title,
GROUPING(e.gender) DESC, e.gender;정렬을 추가하면 된다.

# if(조건, 참값, 거짓값)
# GROUPING() : 어떤 행이 실제 데이터고, 어떤 행이 집계 행인지 구분 (0: 실제 데이터, 1:NULL로 총계행)
# 특정 컬럼이 그룹화 과정에서 집계로 인해 NULL로 표시가 되었는지 확인 (총계행은 컬럼이 NULL로 나타남)
# rollup, cube, grouping sets 에서 사용, 집계된 행이 '실제 데이터'인지, 아니면 rollup/cube로 생성된 '집계행'인지 구분하는데 사용
# WITH ROLLUP 또는 GROUPING SETS을 사용할 때 의미가 있다.
CUBE를 이용한 부서-직무-입사연도 조합별 통계
CUBE는 지정된 컬럼의 모든 가능한 조합에 대해 총계를 생성한다. ROLLUP은 계층적 조합만 생성하지만, CUBE는 모든 컬럼의 부분집합을 다 만들어벌임.
- 컬럼 리스트를 계층적으로 줄여가며 총계를 만듦
- ex) GROUP BY CUBE(A, B, C) (총 조합 수: 2^n)
(A, B, C): 개별 데이터.
(A, B): C에 대한 총계.
(A, C): B에 대한 총계.
(B, C): A에 대한 총계.
(A): B, C에 대한 총계.
(B): A, C에 대한 총계.
(C): A, B에 대한 총계.
(): 전체 총계
(2^3 = 8개 조합)
(MYSQL은 CUBE를 지원하지 않는다. 대신 GROUPING SET이나 UNION ALL로 비슷하게 구현할 수 있다.)
-- CUBE(dept_name, job_title, hire_year)의 효과를 내는 유니온 쿼리
-- (dept_name, job_title, hire_year): 개별 데이터.
SELECT d.dept_name AS dept_name,
j.job_title AS job_title,
YEAR(e.hire_date) AS hire_year,
COUNT(*) AS emp_count,
SUM(e.salary) AS total_salary
FROM employees e
JOIN departments d ON e.dept_id = d.dept_id
JOIN jobs j ON e.job_id = j.job_id
GROUP BY d.dept_name, j.job_title, YEAR(e.hire_date)
UNION ALL
-- 부서-직무별 (dept_name, job_title): 연도 총계.
SELECT d.dept_name AS dept_name,
j.job_title AS job_title,
'전체' AS hire_year,
COUNT(*), SUM(e.salary)
FROM employees e
JOIN departments d ON e.dept_id = d.dept_id
JOIN jobs j ON e.job_id = j.job_id
GROUP BY d.dept_name, j.job_title
UNION ALL
-- 부서-연도별 (dept_name, hire_year): 직무 총계.
SELECT d.dept_name AS dept_name,
'전체' AS job_title,
YEAR(e.hire_date) AS hire_year,
COUNT(*), SUM(e.salary)
FROM employees e
JOIN departments d ON e.dept_id = d.dept_id
GROUP BY d.dept_name, YEAR(e.hire_date)
UNION ALL
-- 직무-연도별 (job_title, hire_year): 부서 총계.
SELECT '전체' AS dept_name,
j.job_title AS job_title,
YEAR(e.hire_date) AS hire_year,
COUNT(*), SUM(e.salary)
FROM employees e
JOIN jobs j ON e.job_id = j.job_id
GROUP BY j.job_title, YEAR(e.hire_date)
UNION ALL
-- 부서별 전체 (dept_name): 직무, 연도 총계.
SELECT d.dept_name AS dept_name,
'전체' AS job_title,
'전체' AS hire_year,
COUNT(*), SUM(e.salary)
FROM employees e
JOIN departments d ON e.dept_id = d.dept_id
GROUP BY d.dept_name
UNION ALL
-- 직무별 전체 (job_title): 부서, 연도 총계.
SELECT '전체' AS dept_name,
j.job_title AS job_title,
'전체' AS hire_year,
COUNT(*), SUM(e.salary)
FROM employees e
JOIN jobs j ON e.job_id = j.job_id
GROUP BY j.job_title
UNION ALL
-- 연도별 전체 (hire_year): 부서, 직무 총계.
SELECT '전체' AS dept_name,
'전체' AS job_title,
YEAR(e.hire_date) AS hire_year,
COUNT(*), SUM(e.salary)
FROM employees e
GROUP BY YEAR(e.hire_date)
UNION ALL
-- 전체 총계 (모든 부서/직무/연도)
SELECT '전체' AS dept_name, '전체' AS job_title, '전체' AS hire_year,
COUNT(*), SUM(e.salary)
FROM employees e;


모든 조합에 대한 행이 출력된다.
GROUPING SETS를 활용한 다양한 조합의 소계/총계 분석
임의의 그룹화 조합에 대한 집계를 수행해보게씀.
GROUPING SETS는 ROLLUP이나 CUBE와 달리, 원하는 특정 그룹화의 조합만 선택하여 결과를 얻을 수 있긔.
예를 들어 부서별 합계와 성별 합계만 한 번에 보고 싶은 그런 상황에서 활용하믄 댐.
(MySQL에서는 마찬가지로 GROUPING SETS를 지원하지 않으므로 UNION으로 대체하게씀 첨부터 오라클로 할 걸...)
-- GROUPING SETS ( (dept_name, gender), (dept_name), (gender), () ) 시뮬레이션
# 부서-성별별 통계
SELECT d.dept_name AS dept_name, e.gender AS gender,
COUNT(*) AS emp_count, SUM(e.salary) AS total_salary
FROM employees e
JOIN departments d ON e.dept_id = d.dept_id
GROUP BY d.dept_name, e.gender
UNION ALL
# 부서별 전체 통계
SELECT d.dept_name AS dept_name, '전체' AS gender,
COUNT(*), SUM(e.salary)
FROM employees e
JOIN departments d ON e.dept_id = d.dept_id
GROUP BY d.dept_name
UNION ALL
# 성별별 전체 통계
SELECT '전체' AS dept_name, e.gender AS gender,
COUNT(*), SUM(e.salary)
FROM employees e
GROUP BY e.gender
UNION ALL
# 전체 총계
SELECT '전체' AS dept_name, '전체' AS gender,
COUNT(*), SUM(e.salary)
FROM employees e;
- 부서별 + 성별별 세부 내역 (첫 번째 SELECT): 각 부서의 남/여 직원 수 및 급여 합계
- 부서별 전체 (두 번째 SELECT): 각 부서의 전체 직원 합계 (성별 무관)
- 성별별 전체 (세 번째 SELECT): 전체 회사를 성별로 구분한 합계 (부서 무관)
- 전사 총계 (네 번째 SELECT): 전체 직원 합계

# GROUPING SETS은 사용자가 원하는 특정 그룹화 조합을 명시적으로 지정해 집계를 생성한다.
# ROLLUP이나 CUBE와는 달리 그룹화 조합을 선택할 수 있어 유연성이 높다.
GROUP BY GROUPING SETS (
(col1, col2, ...) -- 조합 1
(col1, ...) -- 조합 2
(), -- 전체 총계
)
# 각 괄호는 하나의 그룹화 조합을 나타내고, 각 조합에 대해 집계함수를 적용해 결과를 생성할 수 있음
ROLLUP:
계층적 총계 생성.
예: GROUP BY A, B, C WITH ROLLUP → (A, B, C), (A, B), (A), ().
순서에 따라 제한된 조합만 생성.
CUBE:
모든 가능한 조합 생성.
예: CUBE(A, B, C) → (A, B, C), (A, B), (A, C), (B, C), (A), (B), (C), ().
MySQL은 직접 지원하지 않음(대신 GROUPING SETS나 UNION ALL로 구현).
GROUPING SETS:
원하는 조합만 선택.
예: GROUPING SETS((A, B), (A, C), ()) → (A, B), (A, C), 전체 총계만 생성.
ROLLUP이나 CUBE의 부분집합 또는 커스텀 조합 가능.
CASE WHEN을 활용한 피벗(Pivot) 형태 요약표
영어 단어 pivot의 원뜻:
명사: 회전축, 중심점 동사: 축을 중심으로 회전하다
ex) 모니터암 달아서 모니터를 가로 -> 세로 돌리기 ~
데이터를 어떤 기준을 중심으로 회전시켜서
행(row) → 열(column) 또는
열 → 행
형태로 바꾸는 것을 "피벗한다(pivot)"고 표현
피벗 형태로 변환하여 열(column) 기준의 요약표를 만들어보겠긔.
(또) MySQL은 PIVOT 연산에 대한 전용 문법이 없으므로, CASE WHEN 과 집계함수를 조합하여 행을 열로 바꾸겠긔.
피벗 변환의 핵심은 조건부 집계이다.
조건에 따라 값을 집계하고, 그 결과를 별도 컬럼으로 표현하면 행 -> 열 변환 효과를 얻을 수 있다.
부서별 성별 인원 현황표를 만들어 보자!~
SELECT
d.dept_name AS dept_name,
SUM(CASE WHEN e.gender = 'M' THEN 1 ELSE 0 END) AS male_count,
SUM(CASE WHEN e.gender = 'F' THEN 1 ELSE 0 END) AS female_count
FROM employees e
JOIN departments d ON e.dept_id = d.dept_id
GROUP BY d.dept_name;
CASE WHEN e.gender = 'M' THEN 1 ELSE 0 END 표현식은 해당 직원이 남성일 경우 1, 아니면 0을 반환한다. SUM()을 씌우면 그 부서의 남성 직원 수 합계가 구해진다.
이처럼 동일한 그룹 내에서 조건별로 따로 집계한 결과를 각각 컬럼으로 표시하면 행 형식의 데이터를 열 형식으로 볼 수 있다.

부서명 행에 성별 열을 갖는 교차표 형태로 데이터를 확인할 수 있다.
'DB' 카테고리의 다른 글
| 지피티와 함께하는 통계쿼리 공부일기 (5) | 2025.06.27 |
|---|---|
| 펌)MySQL 쓰면서 하지 말아야 할 것 17가지 [13~17] With GPT (0) | 2025.02.09 |
| 펌)MySQL 쓰면서 하지 말아야 할 것 17가지 [7~12] With GPT (0) | 2025.02.09 |
| 펌)MySQL 쓰면서 하지 말아야 할 것 17가지 [1~6] With Claude (1) | 2025.02.09 |
| Mysql PK 생성전략 (+Clusted Index, PostgreSQL Serial) (0) | 2025.02.07 |