elk 스택을 활용한 데이터베이스 연동
https://github.com/LuckyVickys/woosan-back
| 도입

우산 프로젝트는 ElasticSearch를 사용해서 검색 기능을 구현했다.
구현이 용이하도록 간단하고 쉽게 설계한 뒤, 네이버 클라우드 플랫폼 바우처가 있을 때 사용해볼 수 있는 것들을 최대한 사용하기를 목표했다. 기본적인 게시판의 기능을 구현한 이후, 검색 기능 구현을 시작했다.
NCP 에는 "다양한 형태의 데이터를 검색, 분석, 시각화할 수 있는 관리형 OpenSearch 및 Elasticsearch 서비스"인 Search Engine Service가 있고 이를 사용했다.
| MySQL & Elasticsearch 연동 Pipeline
| Board Entity
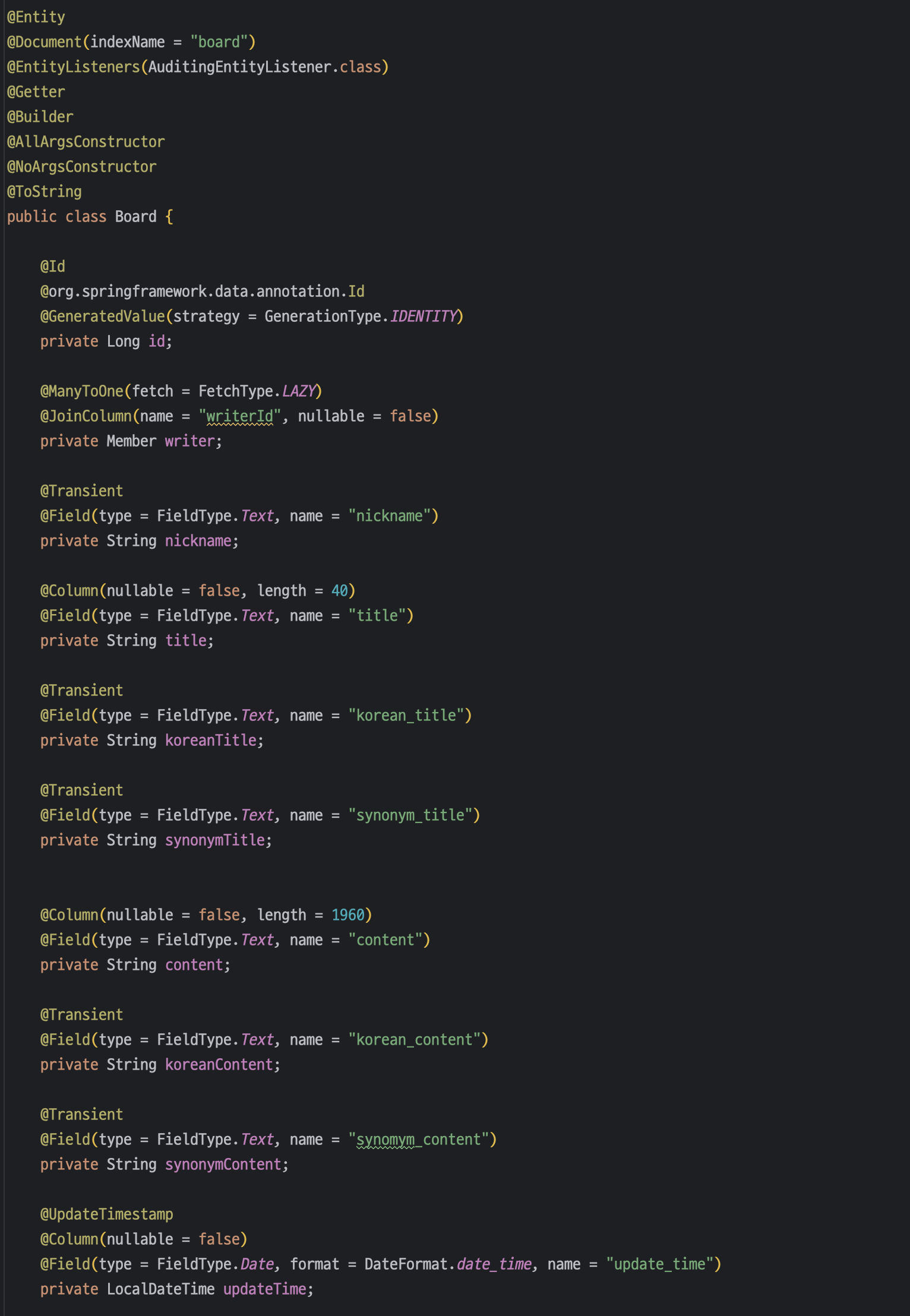
기존 엔티티에 @Document 어노테이션 등을 추가해주었고,
es 인덱스에서는 사용하지만 MySQL 테이블에서는 사용하지 않는 필드에 @Transient 어노테이션을 사용해 정의했다.
| Logstash
input {
jdbc {
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_driver_library => "/etc/logstash/plugin/mysql-connector-java-8.0.30.jar"
jdbc_connection_string => "jdbc:mysql://db-o8kh9-kr.vpc-pub-cdb.ntruss.com:3306/woosan?useSSL=false&allowPublicKeyRetrieval=true"
jdbc_user => "woosan"
jdbc_password => "bitcamp!@#123"
jdbc_paging_enabled => true
jdbc_page_size => 50
statement => "
SELECT b.*, m.nickname AS nickname, UNIX_TIMESTAMP(b.update_time) AS unix_ts_in_secs
FROM board b
JOIN member m ON b.writer_id = m.id
WHERE UNIX_TIMESTAMP(b.update_time) > :sql_last_value
ORDER BY b.update_time ASC
"
record_last_run => false
clean_run => true
tracking_column_type => "numeric"
tracking_column => "unix_ts_in_secs"
use_column_value => true
last_run_metadata_path => "/etc/logstash/data/woosan"
schedule => "*/5 * * * * *"
}
}
filter {
mutate {
remove_field => ["@version", "host"]
add_field => {
"[@metadata][_id]" => "%{id}"
"search_keyword" => "" # search_keyword 필드를 빈 값으로 추가
}
rename => {
"title" => "title"
"content" => "content"
"reg_date" => "reg_date"
"update_time" => "update_time"
"views" => "views"
"likes_count" => "likes_count"
"category_name" => "category_name"
"reply_count" => "reply_count"
"is_deleted" => "is_deleted"
"nickname" => "nickname"
}
copy => {
"title" => "synonym_title"
"content" => "synonym_content"
}
}
ruby {
code => '
def to_chosung(text)
cho = ["ㄱ","ㄲ","ㄴ","ㄷ","ㄸ","ㄹ","ㅁ","ㅂ","ㅃ","ㅅ","ㅆ","ㅇ","ㅈ","ㅉ","ㅊ","ㅋ","ㅌ","ㅍ","ㅎ"]
result = ""
text.each_char do |char|
if char.ord >= 0xAC00 && char.ord <= 0xD7A3
base = char.ord - 0xAC00
cho_index = base / 28 / 21
result += cho[cho_index]
else
result += char
end
end
return result
end
event.set("korean_title", to_chosung(event.get("title")))
event.set("korean_content", to_chosung(event.get("content")))
'
}
}
output {
if [@metadata][_id] {
if [is_deleted] {
elasticsearch {
hosts => ["http://223.130.143.129:9200"]
index => "board"
document_id => "%{id}"
action => "delete"
}
} else {
elasticsearch {
hosts => ["http://223.130.143.129:9200"]
index => "board"
document_id => "%{id}"
action => "update"
doc_as_upsert => true
}
}
}
stdout { codec => rubydebug }
}
input {
http {
port => 5044
}
}
filter {
if [path] =~ "search" {
grok {
match => { "message" => "/search\\?q=%{WORD:search_query}" }
}
mutate {
add_field => { "keyword" => "%{search_query}" }
add_field => { "timestamp" => "%{@timestamp}" }
}
}
}
output {
if [path] =~ "search" {
elasticsearch {
hosts => ["http://223.130.143.129:9200"]
index => "search_keywords"
}
}
stdout { codec => rubydebug }
}
1. 기본 설정
board 테이블의 모든 컬럼과 member 테이블의 nickname 컬럼을 연동했다.
update_time 을 기준으로 변경이 일어난 데이터는 5초마다 동기화되고, 아닌 게시물은 변동없도록 했다.

2. 컬럼명 명시
카멜케이스와 스네이크케이스로 각각 작성한 컬럼명에서 자꾸 에러가 발생해

라고 명시해주었다.
3. 초성 검색
초성 검색을 위해 title, content 컬럼의 문자열 초성을 추출해 연동시에 각각 korean_title과 korean_title 필드에 추가해주도록 설정했다.

4. 삭제 처리
게시글 삭제는 delete가 아니라 update로 "is_deleted" 컬럼을 true로 바꿔주는 것으로 처리했다.
이를 elasticsearch에도 동일하게 반영해, is_deleted = true 조건일 때, es에서 해당 데이터를 삭제 처리했다.

5. 일별 검색 순위
검색 키워드가 입력될 때마다 해당 키워드를 저장하고, 추가된 시간에 따라 집계할 수 있도록 저장했다.



교육과정을 수료하고 바우처 기간이 지나버렸기 때문에 프로젝트를 실행시키려면 다시 elasticsearch 클러스터를 만들어야 한다.
기존에 사용하던 ncp 클러스터 차이를 느껴보고, 로컬 환경에 ELK 스택을 구축하기 위해 docker-compose를 사용했다.
2024.08.10 - [네이버 클라우드 캠프] - NCP Search Engine Service to Local ELK
NCP Search Engine Service to Local ELK
| 배경woosan 프로젝트에서 네이버 클라우드 플랫폼의 Search Engine Service를 사용해 elasticsearch를 사용했다. https://github.com/LuckyVickys/woosan-back/blob/main/Readme.assets/config/ELK.md woosan-back/Readme.assets/config/E
99duuk.tistory.com